[빅데이터를 지탱하는 기술] 트위터 API를 이용한 데이터 파이프라인 만들기 # 1
트위터 API를 이용하여 데이터 파이프라인 만들기
트위터의 API로 트위터 텍스트 데이터를 수집하고 간단한 데이터 파이프라인을 만드는 프로젝트를 진행하였고, 프로젝트는 [빅데이터를 지탱하는 기술] 책에 나오는 예제입니다.
책이 나왔던 당시와 현재 사용하는 기술들의 버전이 차이가 나고, 책에서는 분산처리 환경에 대해서는 나와있지 않기 때문에 개인 프로젝트로 진행하고 작업한 내용을 공유하고자 포스팅을 진행하겠습니다.
먼저 Virtualbox 의 가상머신(VM)을 이용하여 환경을 구축하였습니다.
VM 환경에서 데이터를 분산처리 하기 위하여 구성한 환경은 아래와 같습니다.

모든 VM은 ubuntu-20.04를 사용했습니다.
- master_node : cpu 프로세서 4개, RAM 8GB
- slave_nodes : cpu 프로세서 4개, RAM 4GB
설치한 프레임워크, 데이터베이스, 언어는 다음과 같습니다.
- 프레임워크
- hadoop-3.3.4
- spark-3.3.2
- hive-3.1.3
- presto-0.279
- airflow-2.5.2
- 데이터베이스
- mongodb-4.4
- 언어
- java-8
- python-3.8
먼저 데이터를 수집하기 이전에 하둡 완전 분산 모드로 환경을 구성하였습니다.
환경 구축에 참고한 링크는 아래와 같습니다.
환경설정
각 VM에 ubuntu-20.04를 설치하고 고정 IP를 부여하였습니다.
Hadoop은 Master와 Slave 구조로 되어있고 Master와 Slave들 간의 원활한 통신이 필수적입니다.
하지만 IP가 변하게 되면 통신이 안되기 때문에 고정 IP를 부여했습니다.
- master_node : 192.168.56.101
- slave1_node : 192.168.56.102
- slave2_node : 192.168.56.103
- slave3_node : 192.168.56.104
- slave4_node : 192.168.56.105
그리고 /etc/hosts를 다음과 같이 바꾸었습니다.
먼저 master 입니다.

다음은 slave1입니다.

다른 slave2,3,4들도 동일하게 구성했습니다.
다음은 /etc/hostname입니다.


SSH 설정
master node와 slave node들 간의 암호없이 접속하기 위하여 ssh를 설정했습니다.
ssh를 설정하는 방법은 아래와 같습니다.
ssh-keygen -t rsa 명령어로 ssh키를 생성합니다
- 만약 ssh관련 패키지가 없다면 설치합니다.
- t옵션은 어떤 타입의 암호화 방식을 사용할 것인지 지정하는 옵션입니다, default는 rsa입니다.

id_rsa와 id_rsa.pub파일이 존재하는데 각각 비공개키와 공개키입니다.
비공개키는 로컬 머신에 위치해야하고 공개키는 다른 가상머신으로 복사해야합니다.
cat >> authorized_keys를 통하여 authorized_keys에 id_rsa.pub를 추가하였습니다.

그리고 slave 노드들의 ~/.ssh 폴더에 authorized_keys를 복사하여 붙여넣어줍니다
- 저는
scp명령어를 사용하여 master에서 slave로 옮겼습니다.
master에서 ssh slave1으로 접속을 해보면

master 에서 slave1 으로 접속이 잘되는 것을 확인할 수 있습니다.
Hadoop 설치
Hadoop 공식 홈페이지를 참고하여 Hadoop-3.3.4을 설치하였습니다.
- https://hadoop.apache.org/
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz

master, slave 모두 동일하게 /usr/local 디렉토리 밑에 설치파일을 다운받고 압축을 풀었습니다.
- 사진은 master만 첨부하였습니다.
자바 설치
그 다음 open jdk 8을 설치하였습니다.sudo apt install openjdk-8-jdk
- https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions 참고하시면 java 8을 권장하는 것 같습니다.
Ubuntu 환경변수 설정
ubuntu의 환경변수를 설정하겠습니다.
여러가지 방법이 존재하지만 저는 ~/.bashrc에 추가하여 사용했습니다.
vim ~/.bashrc로 파일을 열고 가장 아래부분에 추가합니다.
#JAVA
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
#HADOOP
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbinsource ~/.bashrc 명령어를 실행합니다.
Hadoop Config 파일 세팅
Hadoop의 configuration 파일들을 세팅하겠습니다.
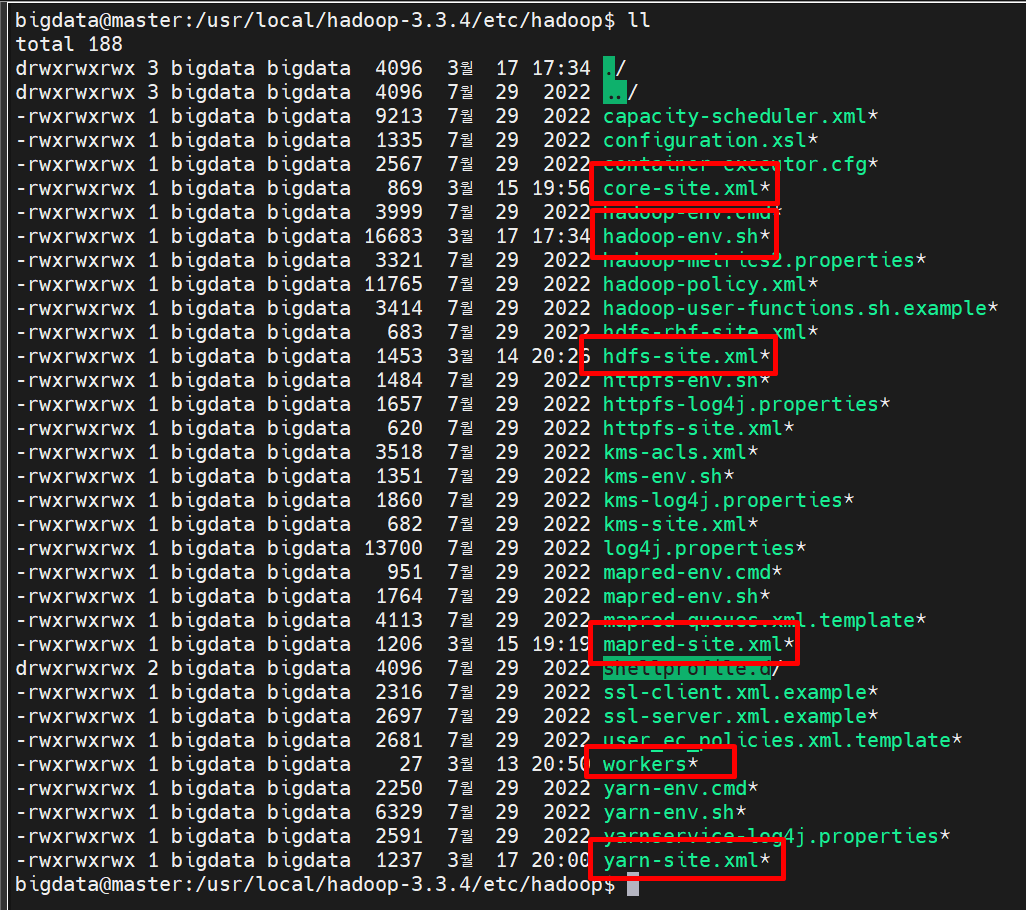
/etc/hadoop밑에 위치하고 있습니다.
master와 slave 모두 동일하게 적용하였습니다.
masterVM에서 작업하고masterVM 을 복제해서 사용하는 것을 추천합니다.
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- namenode 데이터 경로 설정 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop-3.3.4/data/namenode</value>
</property>
<!-- datanode 데이터 경로 설정 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop-3.3.4/data/datanode</value>
</property>
<!-- data 복제 갯수 설정 (장애 대응) -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- seconcdary namenode 설정 -->
<!-- 이미지 정보를 백업하는 기능을 수행 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- log 출력 -->
<property>
<name>yarn.log-aggregation-enables</name>
<value>true</value>
</property>
<!-- mapreduce의 shuffle 메커니즘 존재를 위하여 -->
<!-- maptask 작업 수행하기 위하여 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
workers
slave1
slave2
slave3
slave4
Hadoop 실행
master, slave1,2,3,4 VM을 모두 실행시킨 후에 master에서 Hadoop을 실행합니다.
먼저 hdfs 의 namenode와 datenote를 format하였습니다.
- 맨 처음 hadoop을 실행하기전에 한번만 실행합니다. 매번 실행하지는 않습니다.
hdfs namenode -format
hdfs datanode -format
master VM에서 start-all.sh 명령어를 사용하여 Hadoop을 실행시켜줍니다.

namenode, datanode, secondary namenode .. 등등 시작하는 것을 확인할 수 있습니다.

왼쪽 상단에 master VM에는 Namenode, 오른쪽 상단에 slave1에는 SecondaryNameNode, DataNode가 있는 것을 확인할 수 있고,
나머지 slave에는 DataNode가 있는 것을 확인할 수 있습니다.
master 에서 hdfs dfs -ls 명령어를 쳐보면 hdfs에 생성되어있는 디렉토리를 확인할 수 있습니다.
- 저는 미리 디렉토리를 생성해 놓았기 때문에 보이는 것 입니다.

stop-all.sh 명령어로 hadoop을 끌 수 있고 hadoop을 끄면 다음과 같이 hdfs 명령어를 사용할 수 없습니다.
