![[빅데이터를 지탱하는 기술] 빅데이터의 탐색 # 1](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcwtzPz%2Fbtsf6F1kqUL%2FKHatQOJIy0mK7o2P4RXMmk%2Fimg.png)
크로스 집계의 기본
데이터 시각화 에서 가장 기본이 되는 것은 '크로스 집계' 입니다.
'크로스 집계'의 개념의 대하여 알아보겠습니다.
크로스 테이블
어떤 상품의 월별 매출을 정리한 데이터입니다.

크로스 테이블은 다음의 특징을 가집니다.
- 행 방향(세로)으로는 '상품명'이 나열되고, 열 방향(가로)으로는 '매출 월'이 나열됨
- 행과 열이 교차하는 부분에 숫자 데이터가 들어감
- 사람이 보기 편한 형식
트랜잭션 테이블
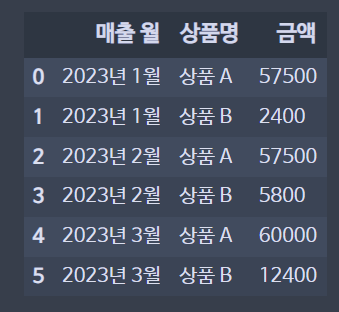
트랜잭션 테이블은 다음의 특징을 가집니다.
- 새로운 행을 추가하는 것은 간단하지만 열을 추가하는 것은 어려움
- 데이터가 증가할 때 행 방향으로 증가하고 열 방향으로 증가하지 않아야 함
- 데이터베이스가 다루기 편한 방식
크로스 집계(cross tabulation)
크로스집계는 트랜잭션 테이블에서 크로스 테이블로 변환하는 과정을 말합니다.
컴퓨터가 다루기 쉬운 데이터의 형식에서 사람이 보기 편한 방식으로 바꾸는 과정이며 구글 스프레드 시트나 엑셀, pandas에서는 피벗 테이블(pivot_table)이 그 기능을 담당하고 있습니다.
df.pivot_table(values='금액', index='상품명', columns='매출 월', aggfunc='sum')
pandas를 이용하여 수백만 레코드를 집계할 수 있지만 그 이상이 되면 너무 느려서 사용하기가 어렵습니다.
대량의 크로스 집계를 하려면 SQL를 이용하여 데이터 집계(aggregation)를 집계함수(aggregate functions)를 사용하여 결과를 확인할 수 있습니다. 여기서는 생략하도록 하겠습니다.
데이터 마트
데이터의 집계와 데이터 시각화 사이에 있는 것이 데이터 마트입니다.
일반적으로는 데이터 마트의 크기가 작다면 시각화하기 쉽습니다.
하지만 데이터 마트의 크기가 작다는 것은 원래 데이터가 포함하고 있는 정보를 잃어버렸다는 의미이고 시각화에서 할 수 있는 것이 적어집니다.
하지만 데이터 마트의 크기가 크다면 많은 정보가 남는다는 장점이 있지만 좋은 시각화를 할 수 없게 될 우려가 있습니다.
이 둘의 관계는 트레이드 오프(trade off) 관계에 있으며 필요에 따라 어느 정도의 정보를 남길 것인가를 결정해야 합니다.
'데이터 엔지니어링' 카테고리의 다른 글
| [빅데이터를 지탱하는 기술] 빅데이터의 탐색 # 3 (0) | 2023.05.17 |
|---|---|
| [빅데이터를 지탱하는 기술] 빅데이터의 탐색 # 2 (0) | 2023.05.17 |
| [빅데이터를 지탱하는 기술] 빅데이터 시대의 데이터 분석 # 2 (0) | 2023.04.18 |
| [빅데이터를 지탱하는 기술] 빅데이터 시대의 데이터 분석 # 1 (0) | 2023.04.11 |
| [빅데이터를 지탱하는 기술] 배경 (0) | 2023.04.11 |