![[kafka] kafka cluster 구축하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FchGpkC%2FbtsD27mVcsZ%2FAAAAAAAAAAAAAAAAAAAAANlzhr-0RM_qqsOJmKG9xwNP2mwepuDGUvavf9nl0sUZ%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DaZc%252FstSr42%252FEhI2Ifd1IoHdtxyI%253D)
데이터 플랫폼 운영업무를 진행하면서 예전 장비가 노후되어 신규 서버가 들어오면서 kafka cluster를 구축하는 일이 생기기도 했고,EOS 문제도 있으며 보안상의 이유로 신규 카프카를 설치해야 하는 경우도 있었습니다.
물론 예전버전의 카프카를 사용하는 경우 rolling upgrade를 진행 할 수도 있습니다.
rolling upgrade는 나중에 이야기를 해보려고 합니다.
이번 포스팅에서는 kafka cluster를 구축해보려고 합니다.
각 버전은 다음과 같습니다.
- zookeeper : 3.6.4
- kafka : 3.0.0
- monitoring : kafka for ui
현재 업무에서는 예전에 구축했던 버전들을 사용하고 있고, rolling upgrade를 위한 복선으로 위와 같은 버전을 사용하겠습니다.
각 버전은 wget 명령어를 통하여 설치하였습니다.
- https://archive.apache.org/dist/zookeeper/zookeeper-3.6.4/apache-zookeeper-3.6.4-bin.tar.gz
- https://archive.apache.org/dist/kafka/3.0.0/kafka_2.13-3.0.0.tgz
zookeeper, kafka는 jvm위에서 동작하는 애플리케이션이기 때문에 각 버전에 맞게 java를 설치해야 합니다.
java를 설치하는 과정은 생략하겠습니다.
여기서는 java 11을 사용했습니다.
내부망을 사용하는 곳은 로컬에서 각 압축파일을 받아 scp로 넘겨서 사용하면 됩니다.
현재 제가 위치한 현장 또한 내부망을 사용하기 때문에 scp로 넘겨서 구축하였습니다.. 지금 생각해보면 어려운 작업은 아니었지만 익숙하지 않은 탓인지.. 당시에는 어렵게 느껴지곤 했습니다.
zookeeper
zookeeper에 대한 설명은 다른 포스팅에서 진행하겠습니다. 오늘은 구축만 진행하겠습니다.
zoo.cfg
아래는 zoo.cfg 설정입니다.
경로는 conf/ 아래에 위치하며 zoo_sample.cfg 파일이 기본적으로 제공하며 해당 파일을 copy하여 사용합니다.
###############
####zoo.cfg####
###############
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir=/tmp/zookeeper
dataDir=/home/manager/data/zookeeper-data
# the port at which the clients will connect
#clientPort=2181
clientPort=12181
#### 생략 ####
server.1=192.168.56.111:12888:13888
server.2=192.168.56.112:12888:13888
server.3=192.168.56.113:12888:13888
dataDir 에 설정된 경로에 myid를 생성합니다.
myid
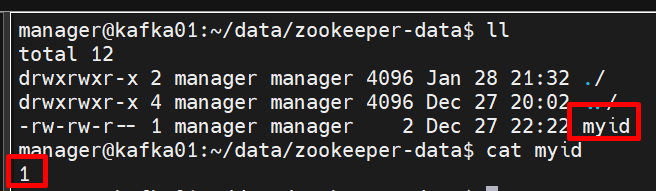
myid에는 각 서버에 맞게 id값을 입력합니다. 보통 server 1 : 1, server 2 : 2 ... 이런식으로 입력합니다.
zkEnv.sh
bin/ 아래에 위치한 zkEnv.sh를 수정하였습니다.
ZOOBINDIR=/home/manager/apps/apache-zookeeper-3.6.4-bin/bin
#ZOOBINDIR="${ZOOBINDIR:-/usr/bin}"
ZOOKEEPER_PREFIX="${ZOOBINDIR}/.."
JAVA_HOME=/home/manager/java/jdk-11.0.2
###생략####가장 상단에 추가했고, JAVA_HOME을 지정해주었습니다.
kafka
다음은 kafka cluster를 구축해보겠습니다.
server.properties
config/ 아래에 위치한 server.properties를 수정합니다.
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://192.168.56.111:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
####생략####
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
#log.dirs=/tmp/kafka-logs
log.dirs=/home/manager/data/kafka-logs
#####생략####
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=192.168.56.111:12181,192.168.56.112:12181,192.168.56.113:12181
####생략#####
#ADD CONFIG
auto.create.topics.enable=false
message.max.bytes=1048576현재 간단한 구축 환경에서 제가 설정한 값은 위와 같습니다.
broker.id는 각 서버마다 고유한 값을 지정해야 합니다. 저는 1번 서버라고 가정했기 때문에 1로 지정하였습니다.
listeners는 간단하게 PLAINTEXT로 설정해주었고, 각 환경에 따라 인증을 필요로 한다면 다른 설정값을 사용해야 합니다.
default로 9092 포트를 사용합니다. 서버 ip와 해당 port를 활용하여 produce, consume을 할 수 있습니다.
log.dirs는 카프카의 server log가 아닌 message(log)가 저장되는 공간입니다.
가장 중요한 공간으로 카프카에 적재되는 데이터가 저장되는 곳으로 용량을 고려하여 설정해야 합니다.
- error, warning과 server log는 logs/ 아래에서 확인할 수 있습니다.
zookeeper.connect는 위에서 설정한 zookeeper의 host ip와 client port를 모두 지정해주면 됩니다.
다른 broker 설정값들은 공식문서를 참고하시면 좋을 것 같습니다.
kafka_server_start.sh
bin/ 아래에 위치한 kafka_server_start.sh를 수정합니다.
export JMX_PORT=9999
####생략####가장 상단에 JMX_PORT를 export 합니다.
이 옵션으로 kafka의 broker, lag, produce info와 같은 정보들을 모니터링할 수 있는 metrics을 제공받을 수 있습니다.
kafka for ui에서 JMX port를 enable하여 사용하기 때문에 해당 옵션이 필요합니다.
kafka_run_class.sh
마찬가지로 bin/ 아래에 위치하고 있습니다.
JAVA_HOME=/home/manager/java/jdk-11.0.2
####생략####상단에 역시 JAVA_HOME을 추가합니다.
실행
zookeeper
~/apache-zookeeper-3.6.4-bin/bin 경로에서 zkServer.sh 를 start 해줍니다.
~/zookeeper_path/bin/zkServer.sh start
status를 입력하면 현재 상태를 알 수 있습니다.
저는 2번 서버가 leader로 지정된 것을 확인할 수 있습니다.
나머지 서버는 follower가 됩니다.
zookeeper를 kill 할때는 start 자리에 stop을 입력하면 됩니다.
kafka
~/kafka_2.13-3.0.0 경로에서 아래와 같이 입력하여 실행합니다.
./bin/kafka-server-start.sh -daemon config/server.propertieskafka를 daemon 즉 백그라운드에서 실행하며 config값은 위에서 설정한 server.properties를 참고합니다.
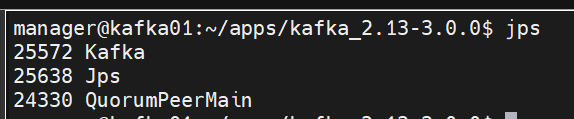
jps를 입력하여 현재 jvm 위에 동작중인 애플리케이션을 확인하면 zookeeper(QuorumPeerMain), kafka가 실행중인 것을 확인할 수 있습니다.
또한 logs/ 디렉토리의 server.log를 확인해보겠습니다.
#####생략#####
[2024-01-28 22:11:18,837] INFO Registered broker 1 at path /brokers/ids/1 with addresses: PLAINTEXT://192.168.56.111:9092, czxid (broker epoch): 4294967358 (kafka.zk.KafkaZkClient)
[2024-01-28 22:11:18,913] INFO [ExpirationReaper-1-topic]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2024-01-28 22:11:18,927] INFO [ExpirationReaper-1-Heartbeat]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2024-01-28 22:11:18,937] INFO [ExpirationReaper-1-Rebalance]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2024-01-28 22:11:18,944] INFO [GroupCoordinator 1]: Starting up. (kafka.coordinator.group.GroupCoordinator)
[2024-01-28 22:11:18,948] INFO [GroupCoordinator 1]: Startup complete. (kafka.coordinator.group.GroupCoordinator)
[2024-01-28 22:11:18,969] INFO [TransactionCoordinator id=1] Starting up. (kafka.coordinator.transaction.TransactionCoordinator)
[2024-01-28 22:11:18,974] INFO [TransactionCoordinator id=1] Startup complete. (kafka.coordinator.transaction.TransactionCoordinator)
[2024-01-28 22:11:18,985] INFO [Transaction Marker Channel Manager 1]: Starting (kafka.coordinator.transaction.TransactionMarkerChannelManager)
[2024-01-28 22:11:19,027] INFO [ExpirationReaper-1-AlterAcls]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2024-01-28 22:11:19,047] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread)
[2024-01-28 22:11:19,069] INFO [SocketServer listenerType=ZK_BROKER, nodeId=1] Starting socket server acceptors and processors (kafka.network.SocketServer)
[2024-01-28 22:11:19,072] INFO [SocketServer listenerType=ZK_BROKER, nodeId=1] Started data-plane acceptor and processor(s) for endpoint : ListenerName(PLAINTEXT) (kafka.network.SocketServer)
[2024-01-28 22:11:19,073] INFO [SocketServer listenerType=ZK_BROKER, nodeId=1] Started socket server acceptors and processors (kafka.network.SocketServer)
[2024-01-28 22:11:19,076] INFO Kafka version: 3.0.0 (org.apache.kafka.common.utils.AppInfoParser)
[2024-01-28 22:11:19,077] INFO Kafka commitId: 8cb0a5e9d3441962 (org.apache.kafka.common.utils.AppInfoParser)
[2024-01-28 22:11:19,077] INFO Kafka startTimeMs: 1706447479073 (org.apache.kafka.common.utils.AppInfoParser)
[2024-01-28 22:11:19,078] INFO [KafkaServer id=1] started (kafka.server.KafkaServer)
[2024-01-28 22:11:19,146] INFO [BrokerToControllerChannelManager broker=1 name=forwarding]: Recorded new controller, from now on will use broker 192.168.56.112:9092 (id: 2 rack: null) (kafka.server.BrokerToControllerRequestThread)
[2024-01-28 22:11:19,193] INFO [BrokerToControllerChannelManager broker=1 name=alterIsr]: Recorded new controller, from now on will use broker 192.168.56.112:9092 (id: 2 rack: null) (kafka.server.BrokerToControllerRequestThread)저는 정상적으로 동작 중인 것을 확인할 수 있습니다.
'데이터 엔지니어링' 카테고리의 다른 글
| [PyFlink] 기록#1 Dictionary in List 처리 (1) | 2024.08.31 |
|---|---|
| [Flink] Flink Architecture (0) | 2024.08.24 |
| [Kafka] kafka 아키텍처와 구성 (0) | 2024.01.21 |
| [Kafka] Apache kafka 소개와 배경 (1) | 2024.01.19 |
| [빅데이터를 지탱하는 기술] 빅데이터의 축적 # 2 (0) | 2023.05.27 |